RAG with KGs for Customer Service Q&A
Overview
This is a heavily-quoted summary of Retrieval-Augmented Generation with Knowledge Graphs for Customer Service Question Answering by Xu et al etc.
Paper Summary
Abstract and Introduction
The conventional retrieval methods in retrieval-augmented generation (RAG) for large language models (LLMs) treat a large corpus of past issue tracking tickets as plain text, ignoring the crucial intra-issue structure and inter-issue relations, which limits performance. We introduce a novel customer service question-answering method that amalgamates RAG with a knowledge graph (KG). Our method constructs a KG from historical issues for use in retrieval, retaining the intra-issue structure and inter-issue relations. During the question-answering phase, our method parses consumer queries and retrieves related sub-graphs from the KG to generate answers. This integration of a KG not only improves retrieval accuracy by preserving customer service structure information but also enhances answering quality by mitigating the effects of text segmentation.
Empirical assessments on our benchmark datasets, utilizing key retrieval (MRR, Recall@K, NDCG@K) and text generation (BLEU, ROUGE, METEOR) metrics, reveal that our method outperforms the baseline by 77.6% in MRR and by 0.32 in BLEU. Our method has been deployed within LinkedIn’s customer service team for approximately six months and has reduced the median per-issue resolution time by 28.6%.
Recent advancements in embedding-based retrieval (EBR), large language models (LLMs), and retrieval-augmented generation (RAG) [8] have significantly enhanced retrieval performance and question-answering capabilities for the technical support of customer service. This process typically unfolds in two stages: first, historical issue tickets are treated as plain text, segmented into smaller chunks to accommodate the context length constraints of embedding models; each chunk is then converted into an embedding vector for retrieval. Second, during the question-answering phase, the system retrieves the most relevant chunks and feeds them as contexts for LLMs to generate answers in response to queries. Despite its straightforward approach, this method encounters several limitations..
Limitation 1 - Compromised Retrieval Accuracy from Ignoring Structures: Issue tracking documents such as Jira [2] possess inherent structure and are interconnected, with references such as “issue A is related to/copied from/caused by issue B.” The conventional approach of compressing documents into text chunks leads to the loss of vital information. Our approach parses issue tickets into trees and further connects individual issue tickets to form an interconnected graph, which maintains this intrinsic relationship among entities, achieving high retrieval performance."
Limitation 2 - Reduced Answer Quality from Segmentation: Segmenting extensive issue tickets into fixed-length segments to accommodate the context length constraints of embedding models can result in the disconnection of related content, leading to incomplete answers. For example, an issue ticket describing an issue at its beginning and its solution at the end may be split during the text segmentation process, resulting in the omission of critical parts of the solution.
Related Work
Question answering (QA) with knowledge graphs (KGs) can be broadly classified into retrieval-based, template-based, and semantic parsing-based methods. Retrieval-based approaches utilize relation extraction [19] or distributed representations [5] to derive answers from KGs, but they face difficulties with questions involving multiple entities. Template-based strategies depend on manually-created templates for encoding complex queries, yet are limited by the scope of available templates [16]. Semantic parsing methods map text to logical forms containing predicates from KGs [4] [14] [21].
Note distributed representations refers to methods that use vector embeddings.
Example of template-based strategy:
(a) Who produced the most films? (b) 〈[person,organization], produced, most films〉 (c)
SELECT ?y WHERE {
?x rdf:type onto:Film .
?x onto:producer ?y .
}
ORDER BY DESC(COUNT(?x)) OFFSET 0 LIMIT 1
Recent advancements in large language models (LLMs) integration with Knowledge Graphs (KGs) have demonstrated notable progress. Jin et al. [7] provide a comprehensive review of this integration, categorizing the roles of LLMs as Predictors, Encoders, and Aligners. For graph-based reasoning, Think-on-Graph [15] and Reasoning-on-Graph [10] enhance LLMs’ reasoning abilities by integrating KGs. Yang et al. [20] propose augmenting LLMs’ factual reasoning across various training phases using KGs. For LLM-based question answering, Wen et al.’s Mindmap [18] and Qi et al. [13] employ KGs to boost LLM inference capabilities in specialized domains such as medicine and food. These contributions underscore the increasing efficacy of LLM and KG combinations in enhancing information retrieval and reasoning tasks.
There seem to be a lot of great papers here for the interested reader:
- [7] Jin, X., Wang, Y., Zhang, Y., & Wang, Y. (2023). Large Language Models on Graphs: A Comprehensive Survey.
- [10] Luo, L., Li, Y.-F., Haffari, G., & Pan, S. (2023). Reasoning on Graphs: Faithful and Interpretable Large Language Model Reasoning.
- [13] Qi, Y., Li, H., & Wang, Y. (2023). Traditional Chinese Medicine Knowledge Graph Construction Based on Large Language Models.
- [15] Lo, P.-C., Tsai, Y.-H., Lim, E.-P., & Hwang, S.-Y. (2023). Think-on-Graph: Deep and Responsible Reasoning of Large Language Model with Knowledge Graph.
- [18] Wen, Y., Wang, Z., & Sun, J. (2023). MindMap: Knowledge Graph Prompting Sparks Graph of Thoughts in Large Language Models.
- [20] Yang, J., Wang, Y., & Zhang, Y. (2023). Integrating Large Language Models and Knowledge Graphs for Enhanced Reasoning.
Methods
Our system (Figure 1) comprises two phases: First, during the KG construction phase, our system constructs a comprehensive knowledge graph from historical customer service issue tickets [employing] a dual-level architecture that segregates intra-issue and inter-issue relations. The Intra-issue Tree $\mathcal{T}_i(\mathcal{N}, \mathcal{E}, \mathcal{R})$ models each ticket $t_i$ as a tree, where each node $n \in \mathcal{N}$, identified by a unique combination $(i, s)$, corresponds to a distinct section $s$ of ticket $t_i$, and each edge $e \in \mathcal{E}$ and $r \in \mathcal{R}$ signifies the hierarchical connection and type of relations between these sections.
Inter-issue Graph $\mathcal{G}(\mathcal{T}, \mathcal{E}, \mathcal{R})$ represents the network of connections across different tickets, incorporating both explicit links $\mathcal{E}_{exp}$ [
CLONE_FROM], defined in issue tracking tickets, and implicit connections $\mathcal{E}_{imp}$ [SIMILAR_TO], derived from semantic similarity between tickets. For implicit connections, we leverage cosine similarity between the embedding vectors of ticket titles, a method adaptable to specific use cases.
I wonder there is room for improvement regarding the method for determining ticket similarity.
- Intra-Ticket Parsing Phase: This phase transforms each text-based ticket 𝑡𝑖 into a tree representation T𝑖 . We employ a hybrid methodology, initially utilizing rule-based extraction for predefined fields, such as code sections identified via keywords. Subsequently, for text not amenable to rule-based parsing, we engage an LLM for parsing. The LLM is directed by a YAML template $\mathcal{T}_{\text{template}}$ , representing in graph the ticket sections routinely utilized by customer support. 2) Inter-Ticket Connection Phase: Here, individual trees $\mathcal{T}_i$ are amalgamated into a comprehensive graph $\mathcal{G}$. Explicit connections $\mathcal{E}_{\text{exp}}$ are delineated as specified within tickets, exemplified by designated fields in Jira [2]. Implicit connections $\mathcal{E}_{\text{imp}}$ are inferred from textual-semantic similarities across ticket titles, employing embedding techniques and a threshold mechanism to discern the most relevant tickets for each issue ticket.
So, we’ve got some use of ChatGPT hidden in here, but hard to think of a better tool under the circumstances.
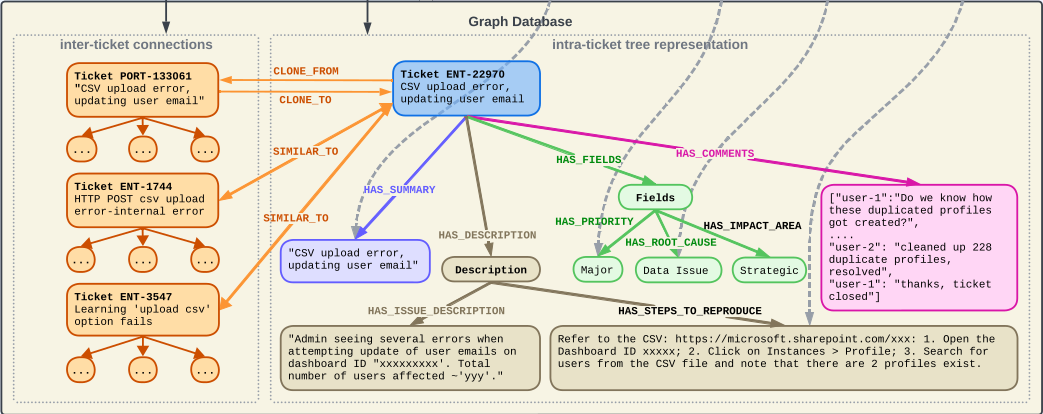
To support online embedding-based retrieval, we generate embeddings for graph node values using pre-trained text-embedding models like BERT [6] and E5 [17], specifically targeting nodes for text-rich sections such as “issue summary”, “issue description”, and “steps to reproduce”, etc. These embeddings are then stored in a vector database (for instance, QDrant [12])). For most cases the text-length within each node can meet the text-embedding model’s context length constraints, but for certain lengthy texts, we can safely divide the text into smaller chunks for individual embedding without worrying about quality since the text all belong to the same section.
Does this mean potentially multiple chunks per node?
[D]uring the question-answering phase, our method parses consumer queries to identify named entities and intents.
Example query:
How to reproduce the login issue where a user can’t log in to LinkedIn?
In this step, we extract the named entities [to] $\mathcal{P}$ of type $\text{Map}(\mathcal{N} \to \mathcal{V})$ and the query intent set $\mathcal{I}$ from each user query $q$. The method involves parsing each query $q$ into a key-value pair, where each key $n$, mentioned within the query, corresponds to an element in the graph template $\mathcal{T}_{\text{template}}$ [e.g. “issue summary”], and the value $v$ represents the information extracted from the query [e.g. “login issue”].
Concurrently, the query intents $\mathcal{I}$ include the entities mentioned in the graph template $\mathcal{T}_{\text{template}}$ that the query aims to address. We leverage LLM with a suitable prompt in this parsing process. For instance, given the query $q = \text{"How to reproduce the login issue where a user can’t log in to LinkedIn?"}$, the extracted entity is $\mathcal{P} = \text{Map}(\text{"issue summary"} \to \text{"login issue"}, \text{"issue description"} \to \text{"user can’t log in to LinkedIn"})$, and the intent set is $\mathcal{I} = \text{Set}("fix solution")$
Entity detection (derivation of $\mathcal{P}$) and intent classification (derivation of $\mathcal{I}$) are performed by ChatGPT:
$$ \begin{gather} \mathcal{P}, \mathcal{I} = \text{LLM}(q, \mathcal{T}_{\text{template}}, \text{prompt}) \end{gather} $$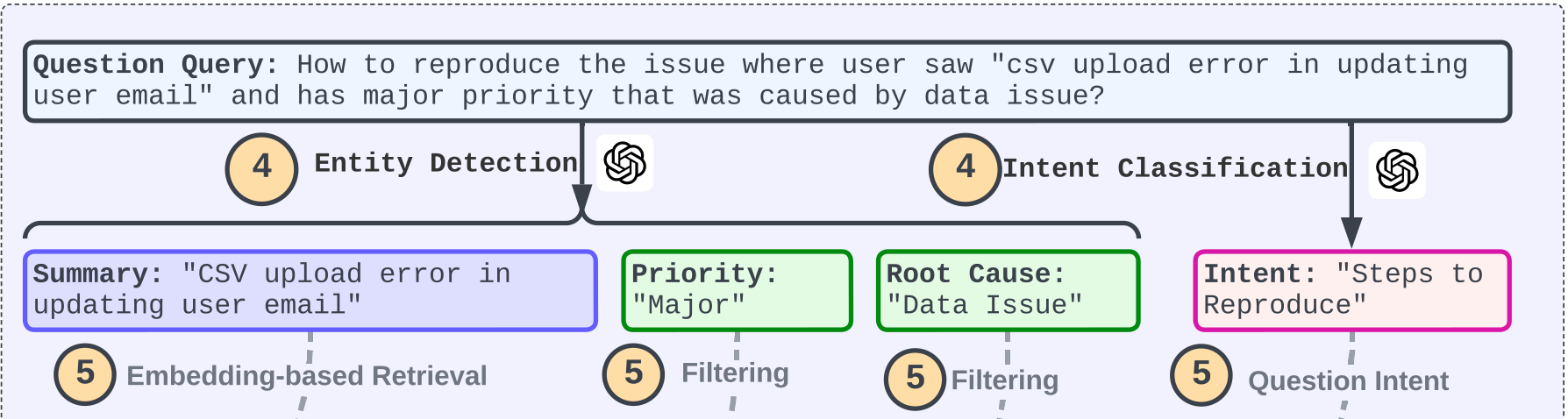
Embedding-based Retrieval of Sub-graphs. Our method extracts pertinent sub-graphs from the knowledge graph, aligned with user-provided specifics such as “issue description” and “issue summary”, as well as user intentions like “fix solution”. This process consists of two primary steps…
[1.] In the [Embedding-based Retrieval]-based ticket identification step, the top $K_{\text{ticket}}$ most relevant historical issue tickets are pinpointed by harnessing the named entity set $\mathcal{P}$ derived from user queries. For each entity pair $(k, v) \in \mathcal{P}$, cosine similarity is computed between the entity value $v$ and all graph nodes $n$ corresponding to section $k$ via pretrained text embeddings.
So, for an issue description key-value pair we check for similarity with all issue description nodes.
Aggregating these node-level scores to ticket-level by summing contributions from nodes belonging to the same ticket, we rank and select the top $K_{\text{ticket}}$ tickets.
We have a similarity score for each ticket tree $T_i$:
$$ \begin{gather} S_{T_i} = \sum_{(k, v) \in \mathcal{P}} \left[ \sum_{n \in T_i} \mathbb{I}\{n.\text{sec} = k\} \cdot \cos\left( \text{embed}(v), \text{embed}(n.\text{text}) \right) \right] \end{gather} $$- note the indicator function $\mathbb{I}$ returns $1$ if the key matches, else $0$
[2.] In the LLM-driven subgraph extraction step, the system first rephrases the original user query $q$ to include the retrieved ticket ID; the modified query $q'$ is then translated into a graph database language, such as Cypher for Neo4j for question answering. For instance, from the initial query $q = \text{"how to reproduce the issue where user saw ’csv upload error in updating user email’ with major priority due to a data issue"}$, the query is reformulated to $\text{"how to reproduce ’ENT-22970’"}$ and thereafter transposed into the Cypher query
MATCH (j:Ticket {ticket_ID: ’ENT-22970’}) -[:HAS_DESCRIPTION]-> (description:Description) -[:HAS_STEPS_TO_REPRODUCE]-> (steps_to_reproduce: StepsToReproduce) RETURN steps_to_reproduce.value.
Answers are synthesized by correlating retrieved data from [the EBR-based ticket identification step and the LLM-driven subgraph extraction step] with the initial query. The LLM serves as a decoder to formulate responses to user inquiries given the retrieved information.
So, the LLM is fed the top $k$ relevant tickets along with a potential exact match along with the initial query, furnishing a response.
Experiment Design
Our evaluation employed a curated “golden” dataset comprising typical queries, support tickets, and their authoritative solutions. The control group operated with conventional text-based EBR, while the experimental group applied the methodology outlined in this study. For both groups, we utilized the same LLM, specifically GPT-4 [1], and the same embedding model, E5 [17]. We measured retrieval efficacy using Mean Reciprocal Rank (MRR), recall@K, and NDCG@K. MRR gauges the average inverse rank of the initial correct response, recall@K determines the likelihood of a relevant item’s appearance within the top K selections, and NDCG@K appraises the rank quality by considering both position and pertinence of items.
For question-answering performance, we juxtaposed the “golden” solutions against the generated responses, utilizing metrics such as BLEU [11], ROUGE [9], and METEOR [3] scores.
Results
[Our method] surpasses the baseline by 77.6% in MRR and by 0.32 in BLEU score
Table 1: Retrieval Performance
| MRR | Recall@K K=1 | Recall@K K=3 | NDCG@K K=1 | NDCG@K K=3 | |
|---|---|---|---|---|---|
| Baseline | 0.522 | 0.400 | 0.640 | 0.400 | 0.520 |
| Experiment | 0.927 | 0.860 | 1.000 | 0.860 | 0.946 |
Table 2: Question Answering Performance
| BLEU | METEOR | ROUGE | |
|---|---|---|---|
| Baseline | 0.057 | 0.279 | 0.183 |
| Experiment | 0.377 | 0.613 | 0.546 |
We deployed our method within LinkedIn’s customer service team, covering multiple product lines. The team was split randomly into two groups: one used our system, while the other stuck to traditional manual methods. As shown in Table 3, the group using our system achieved significant gains, reducing the median resolution time per issue by 28.6%.
Table 3: Customer Support Issue Resolution Time
| Group | Mean | P50 | P90 |
|---|---|---|---|
| Tool Not Used | 40 Hours | 7 Hours | 87 Hours |
| Tool Used | 15 hours | 5 hours | 47 hours |
Conclusions
Future work will focus on: developing an automated mechanism for extracting graph templates, enhancing system adaptability; investigating dynamic updates to the knowledge graph based on user queries to improve real-time responsiveness; and exploring the system’s applicability in other contexts beyond customer service.